Three stages, one forward pass.
Classical OCR is a pipeline of three modules. First a detector draws boxes around text regions; then a recogniser reads the pixels inside each box into characters; finally a post-processor corrects the output and resolves reading order. Each module can fail independently, and the errors compound.
Detection granularity has shifted from words to lines to whole regions. Word-level detection — the CRAFT / EAST tradition — still dominates scene text. Line-level dominates documents. Region-level detection is where modern vision-language models thrive: they see entire paragraphs as semantic units and preserve layout without a separate analysis step.
Recognition used to be CTC — Connectionist Temporal Classification — which is fast but treats each character as independent. Attention-based decoders, standard since 2018, let the model condition each character on the whole image. That is why modern OCR finally stops confusing “rn” with “m” and “l” with “1”.
Post-processing is the unsexy part: language-model correction (“teh” to “the”), layout analysis (read left column before right), table structure recognition (scored by TEDS), and confidence filtering. It is also where traditional pipelines most often embarrass themselves.
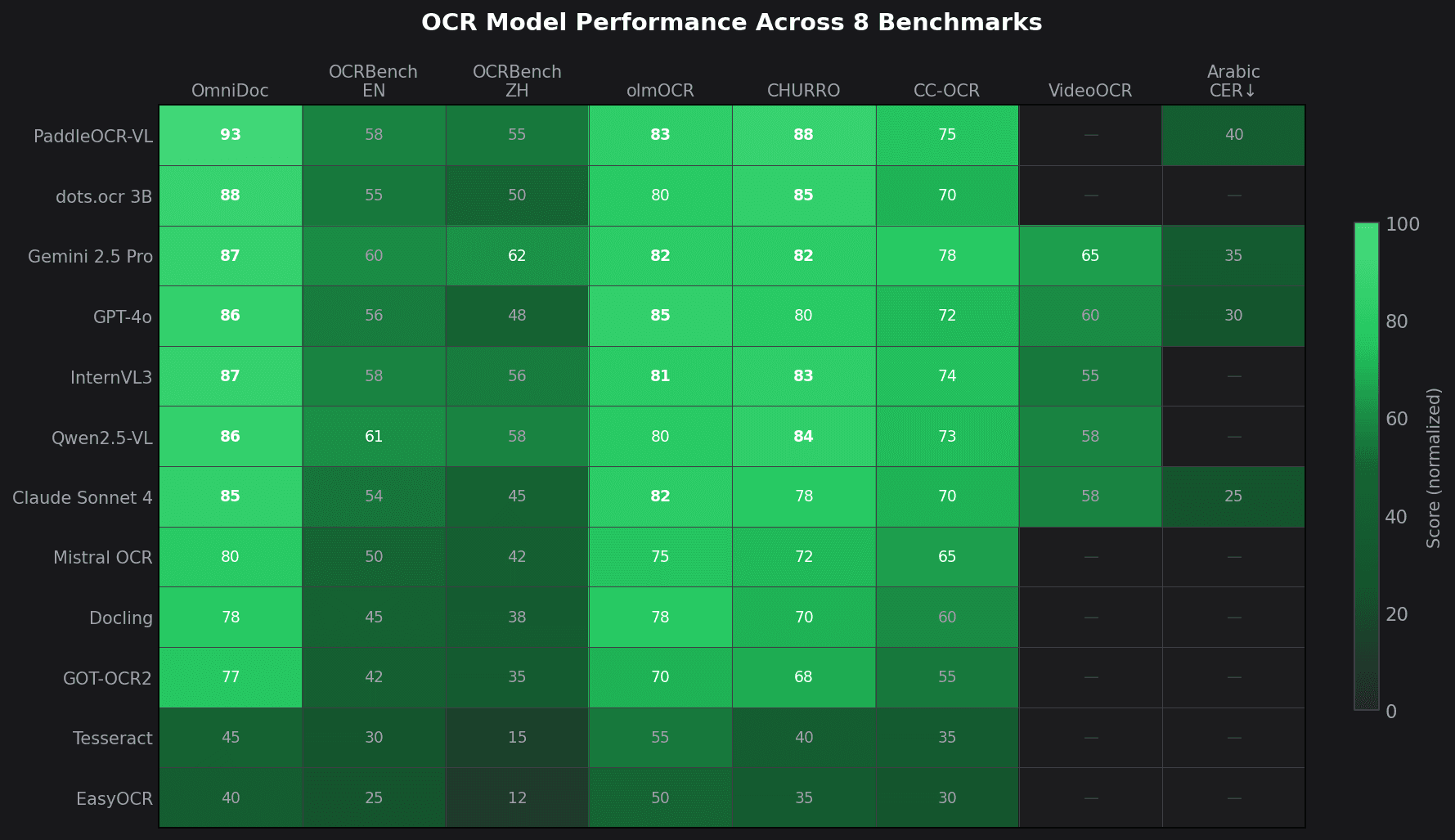
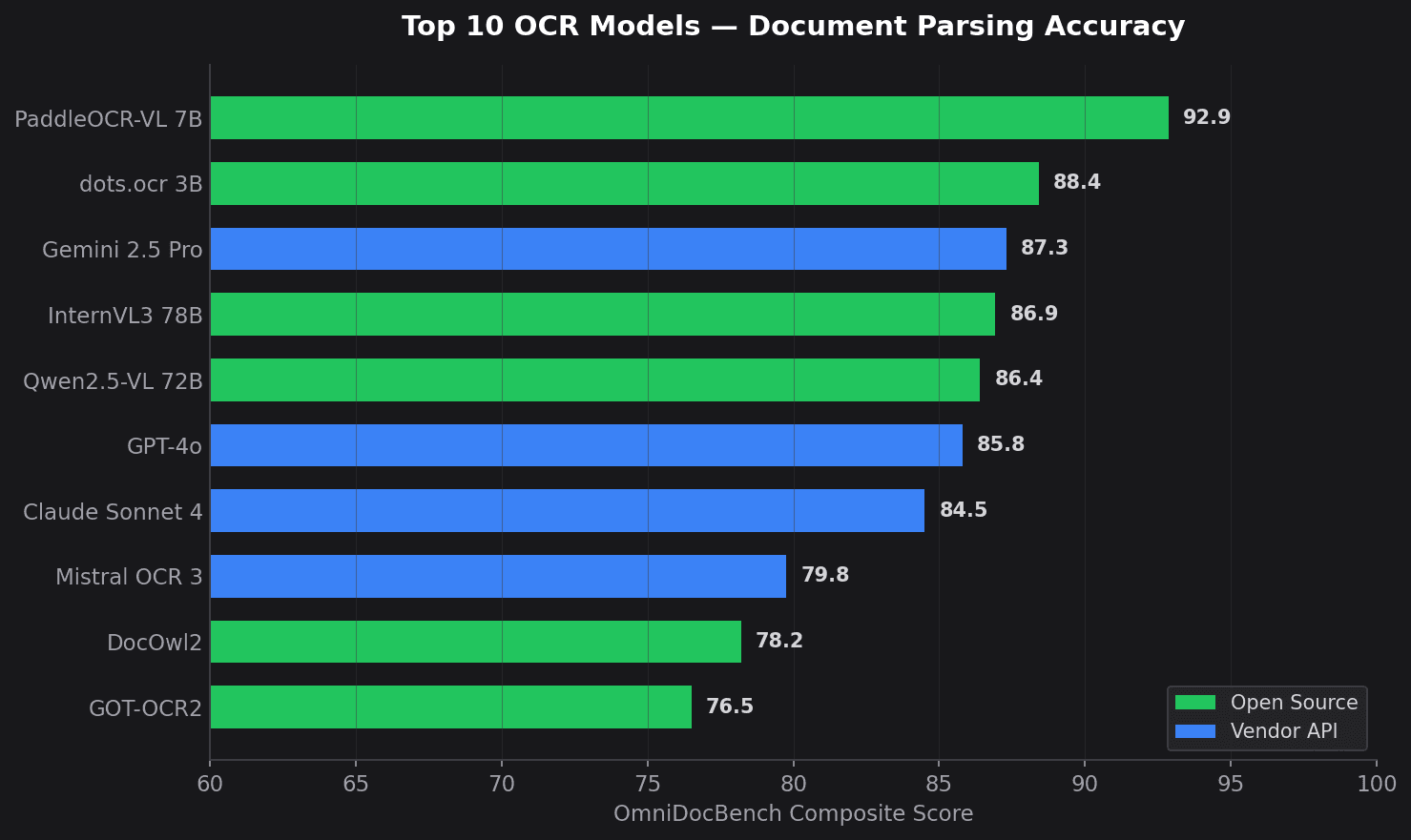
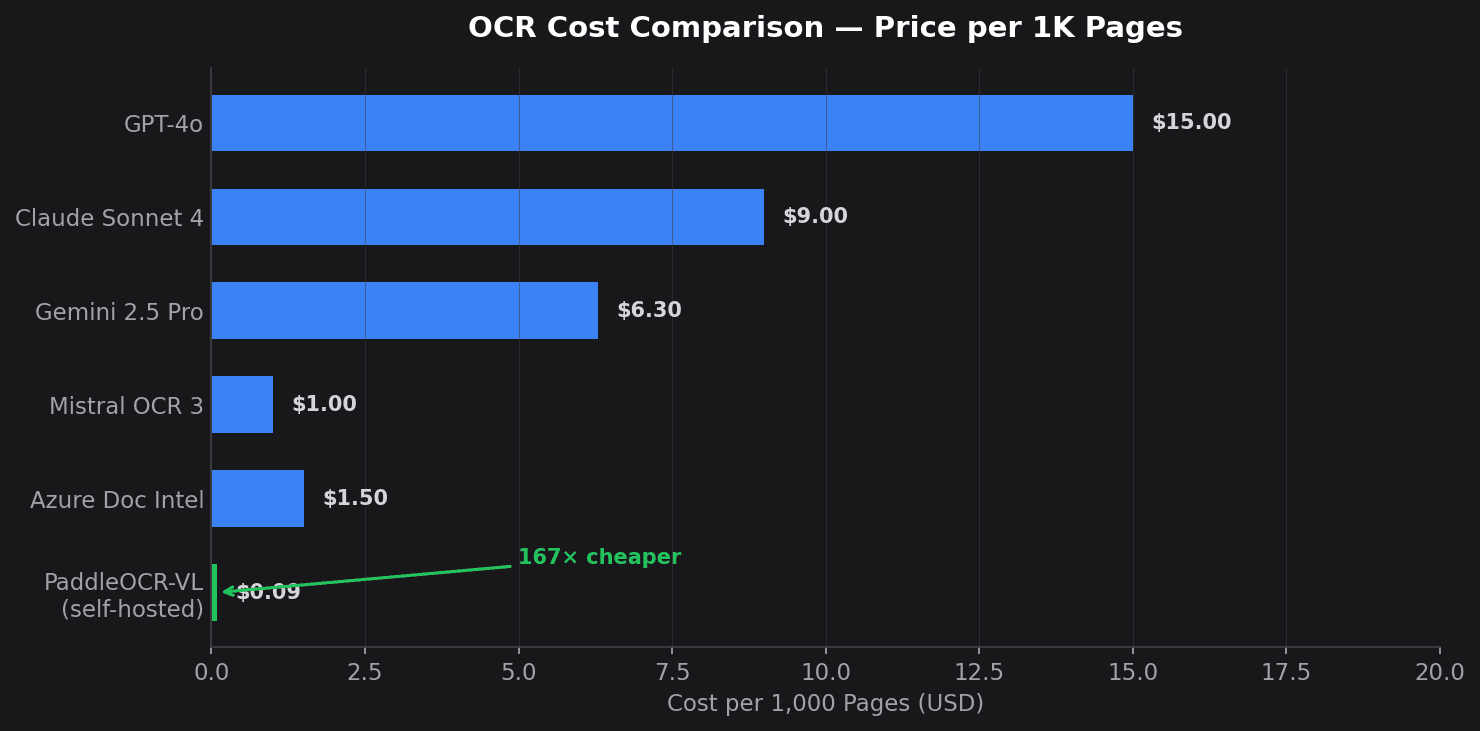
The 2023–2026 shift is that vision-language models fold all three stages into a single forward pass. They read the document the way a literate human does — as one object, with layout, structure and language considered at once. Traditional OCR is no longer SOTA for complex document understanding, but Tesseract, EasyOCR and classic PaddleOCR still matter for CPU-only, air-gapped, deterministic and simple high-throughput scans.