Editorial-design sweep, structured score submissions, lineage build-out.
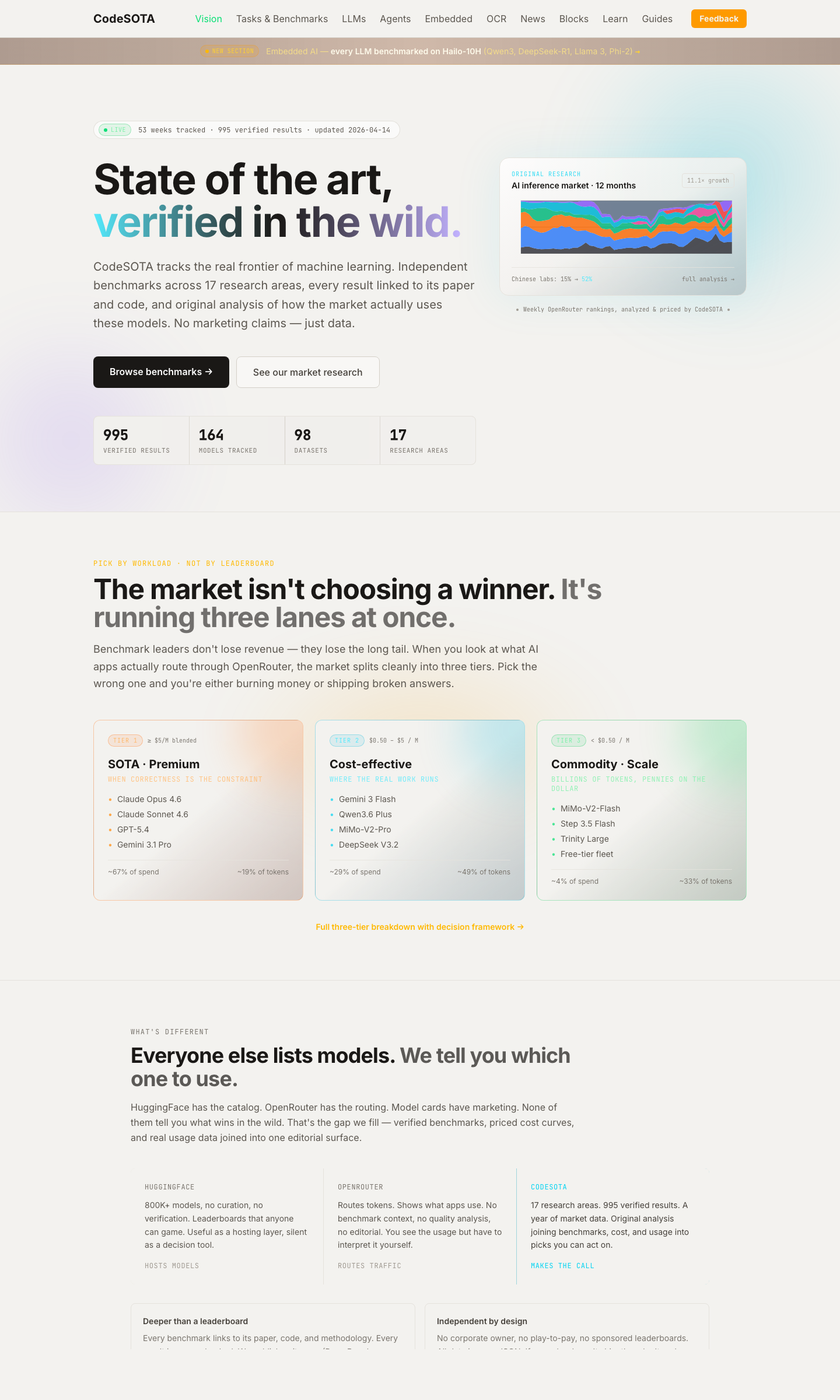
Largest single-day visual rebrand to date. ~50 pages migrated from the legacy dark-Tailwind layout to the editorial .cs design system: /tasks/* leaderboards (document-ocr, code-generation, text-to-image, text-to-speech), /llm/* benchmark hubs (coding-benchmarks, humaneval-mbpp, gsm8k-math, reasoning-benchmarks), /agentic/* head-to-heads (Aider/Devin/Codex/Cursor vs Claude Code), /speech/* TTS comparisons (ElevenLabs/Cartesia/OpenAI/Google + audiobook guide), and the bulk of /ocr/* (vendor profiles, head-to-heads, best-for guides, brand pages with sub-routes, meta and decision pages, deep-dive benchmarks). Each page wraps in `
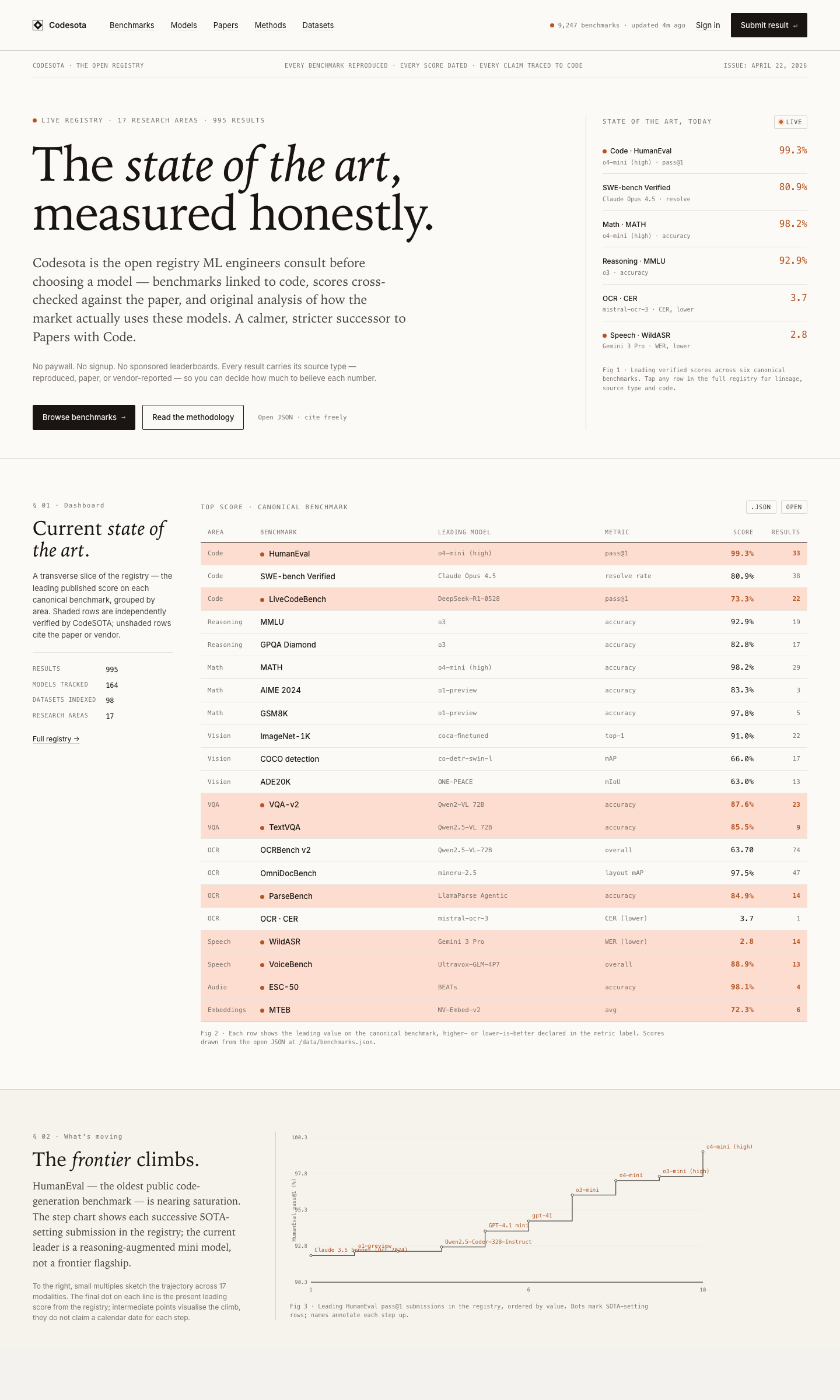
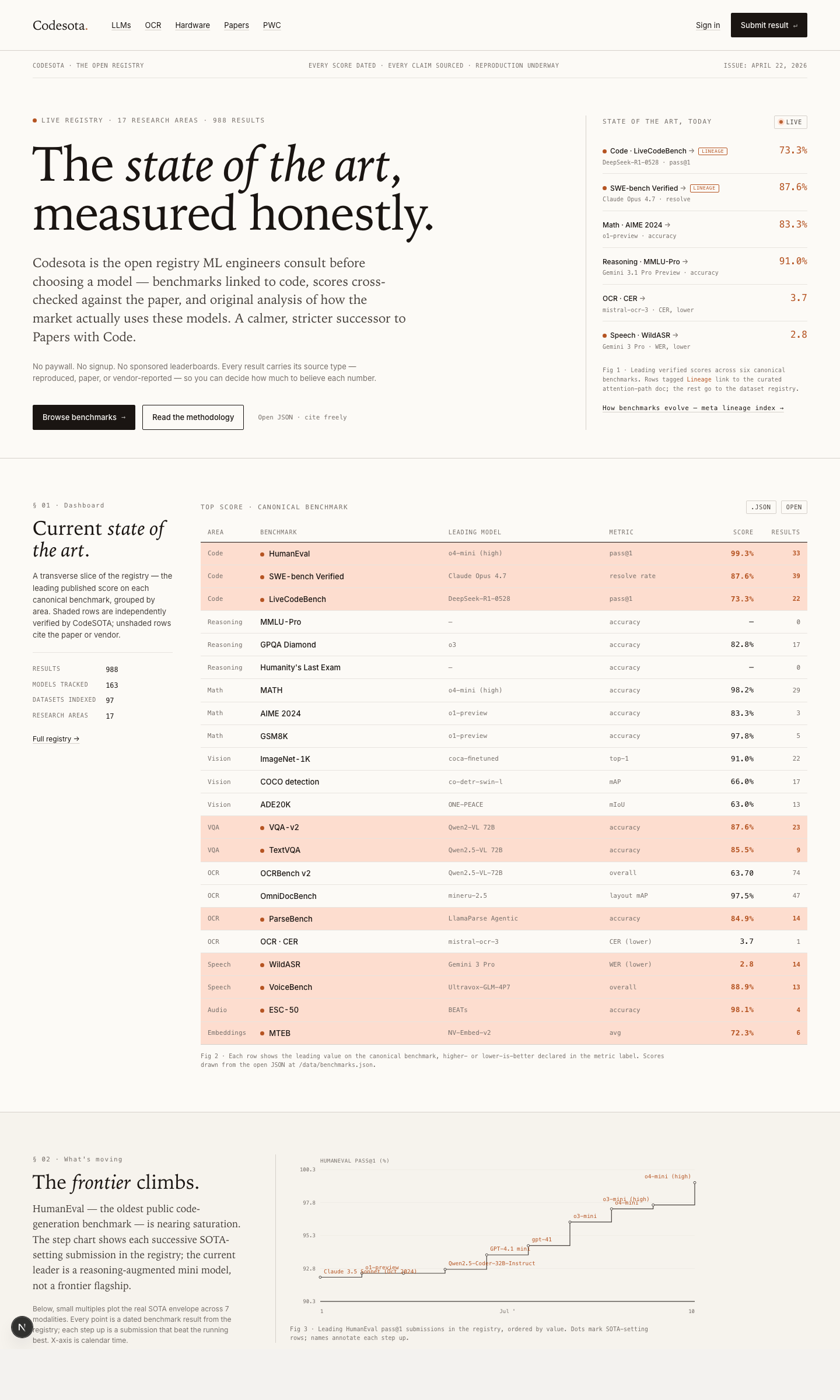
` with running head + serif H1 + alternating paper/paper-2 sections + tabular data with `tr.sota` highlights — wrapper-only, all numbers, code samples, and JSON-LD schemas preserved verbatim. Curriculum lessons (level-0 and level-1 of /learn/lessons/*) brought into the cream palette via the existing `.lesson-body` CSS bridge. New /contribute/score endpoint: structured submission form with benchmark autocomplete (datalist of every dataset whose `metric_direction` is configured), validating posts to /api/submissions, auto-acked via Resend, queued in `community_submissions`. CTA on /contribute promotes "Submit a score" first now, with repo and paper-suggest as secondary. Lineage data: vision (ImageNet → COCO → SA-1B → SA-V, with SAM/SAM 2 properly framed as reference models, not benchmarks), audio (ESC-50 → AudioSet → Clotho → audio-text retrieval → AudioBench → VoiceBench, CLAP corrected to a model not a benchmark), agentic (GAIA → AgentBench → WebArena → OSWorld → tau-bench → SWE-bench Verified → SWE-bench Pro). Benchmark detail pages: /benchmark/livecodebench and /benchmark/terminal-bench now derive SOTA history from DB merged with curated fallback (no more chart/leaderboard mismatch); /benchmark/hle and /hardware (with TOPS leaderboard) brought into editorial style.
Registry as product — /api/sota, coding lineage, contamination-tax methodology.
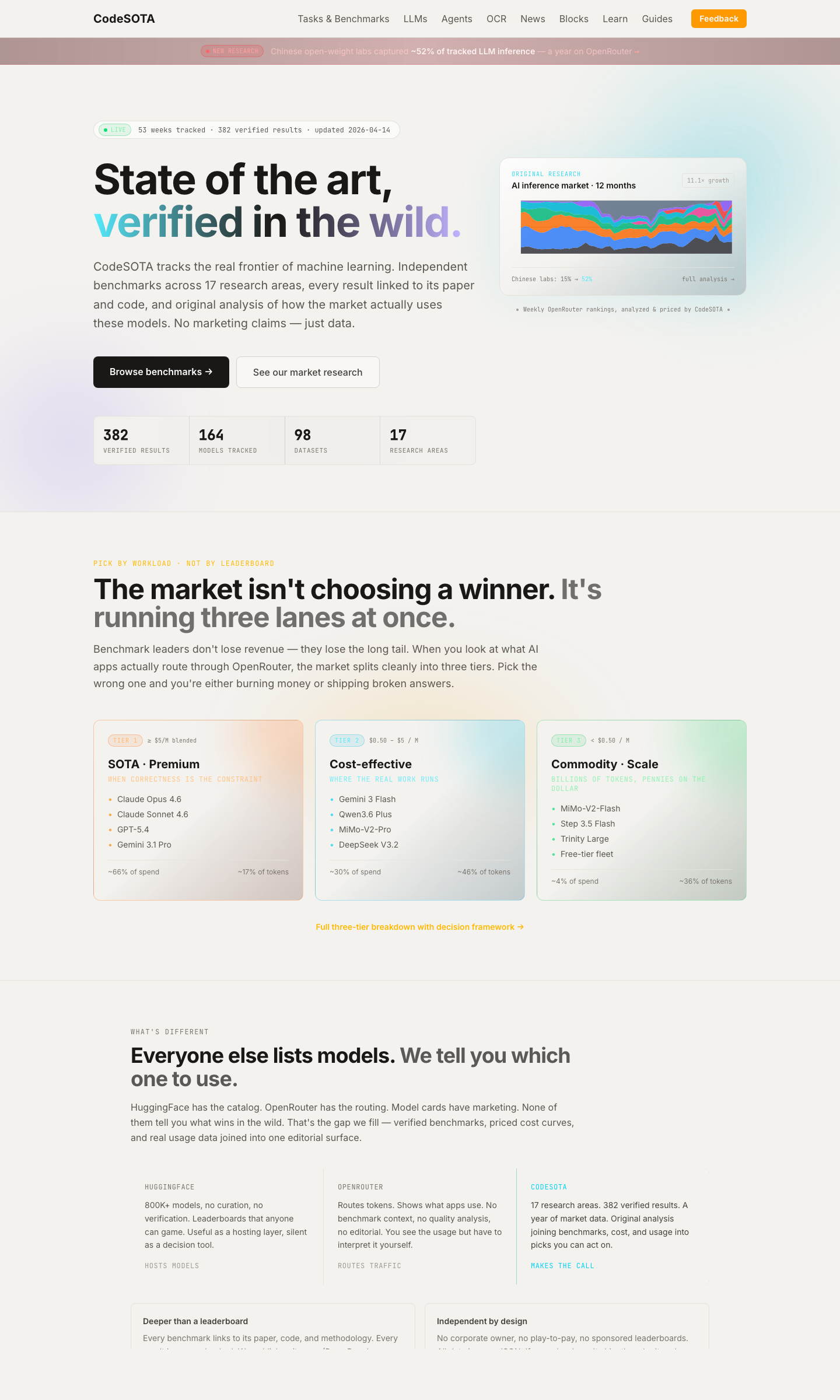
Three threads, one direction: Codesota becomes a callable registry instead of a static reference. /api/sota is live — a free, agent-discoverable, CORS-open JSON endpoint that returns the current dated, sourced SOTA pick per task with full provenance and a stable snapshot_id you can cache against. Short aliases accepted (/api/sota/ocr → document-ocr, /api/sota/code → code-generation, plus asr, tts, vqa, caption, t2i, t2v). Reserved fields (provider_hints, cost_per_1k_usd, benchmark_version) publish as null in v0.1 — better than fabricating them. Documented at /api-landing/sota with full schema, error codes, CORS, rate-limit policy, and the S&P-vs-broker framing that says we explicitly do not route inference. Coding lineage added to public/data/lineages — HumanEval → HumanEval+ → LiveCodeBench → SWE-bench → SWE-bench Verified → SWE-bench Pro, with statuses tracking the Sep 2025 OpenAI announcement that Verified is contaminated. LineageStrip component renders predecessors / current / successors on every benchmark page where the dataset_id appears in any lineage. /methodology § 11 Contamination tax added — the gold-vs-independent two-score framework, OmniDocBench named as first target. robots.txt allowlists /api/sota/ for AI and search crawlers; llms.txt documents the schema so LLMs grounding answers in the site find the contract.
Navigation hygiene, /benchmark crash fix, /ocr hero rewrite.
Inbound-link audit found dozens of orphans. Footer rebalanced: Domains gained Speech-to-Text and Text-to-Speech; Tools gained OCR Benchmark Priority, Polish OCR, Polish LLM, and the new /api/sota docs link; Codesota gained Benchmark Lineages and Activity Log. /llm index now links its six SEO sub-pages (coding-benchmarks, humaneval-mbpp, gsm8k-math, math-benchmarks, reasoning-benchmarks, open-models) under a new Deep-dives section. /trending added to robots disallow — internal pageview dashboard, not search-discoverable. Dead code removed: src/components/SiteFooter.tsx + Header.tsx (271 LOC, unused — the live footer is in app/landing/components.tsx); /iceberg and /beta page redirects moved to next.config.ts as permanent 308s and the page files deleted. Bug fix: /benchmark/[id] crashed client-side on livecodebench and ocr-cer-benchmark — Postgres NUMERIC columns serialized as strings via the Neon driver under UNION ALL, breaking Recharts math on TrendChart hydration. Fixed with ::float casts in all three union branches and a parseFloat fallback in JS. /ocr hero dropped "the traffic king of our registry" for content-first framing. Every plain-text model mention on /ocr now resolves to /model/{id} via ModelRef + Prose, with vendor hints expanded to cover OCR-specific names (tesseract, easyocr, trocr, nougat, docling, chandra, donut, glm-ocr, dots.ocr) — works site-wide, not just on /ocr. /papers-with-code softened from "every benchmark is reproduced" to "every benchmark is traceable" — acknowledges that closed APIs and non-deterministic outputs need dated source links and prompt templates rather than literal code reproduction.