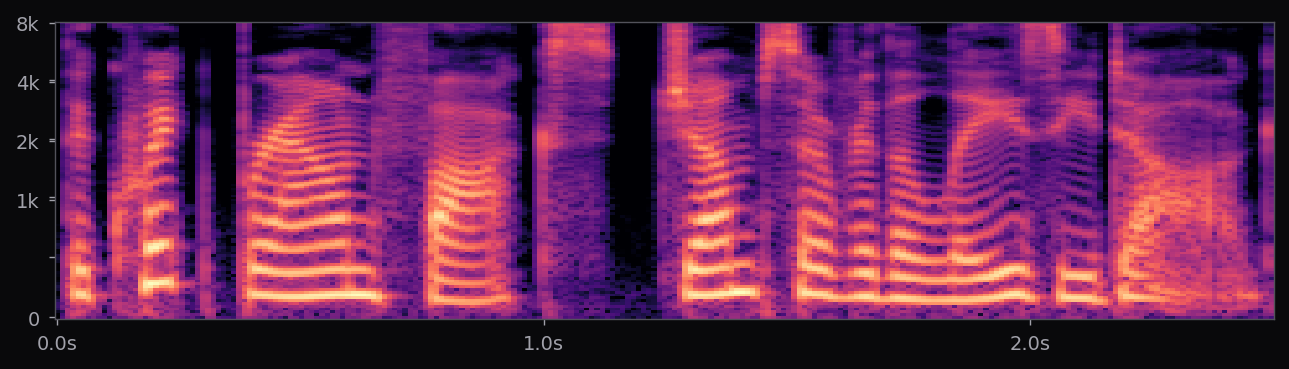
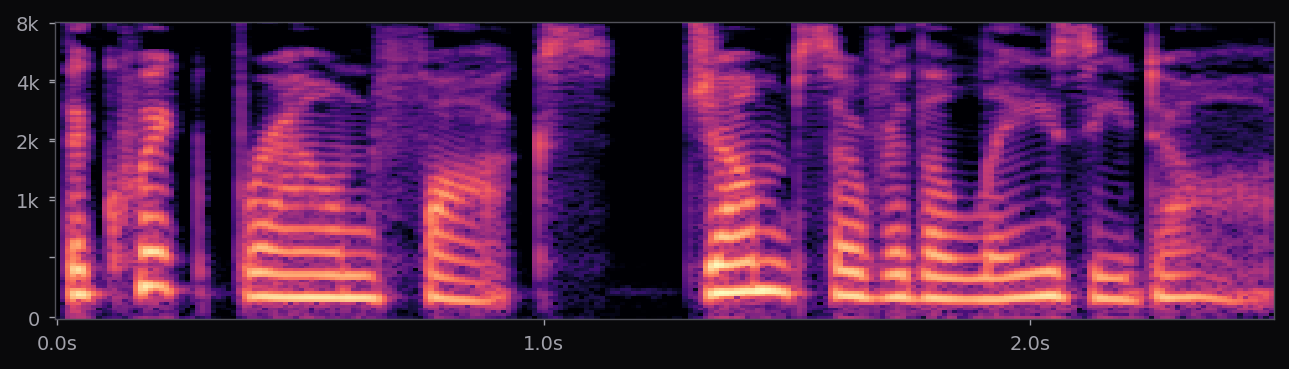
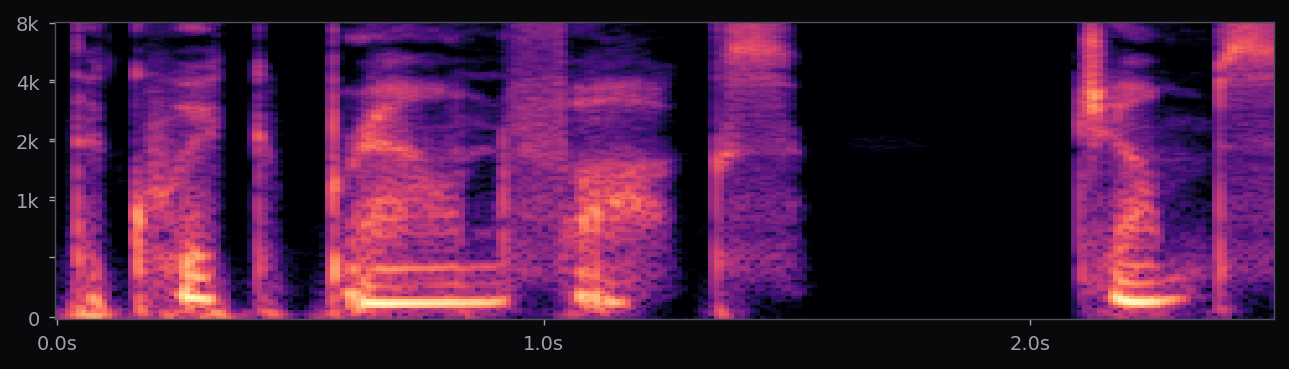
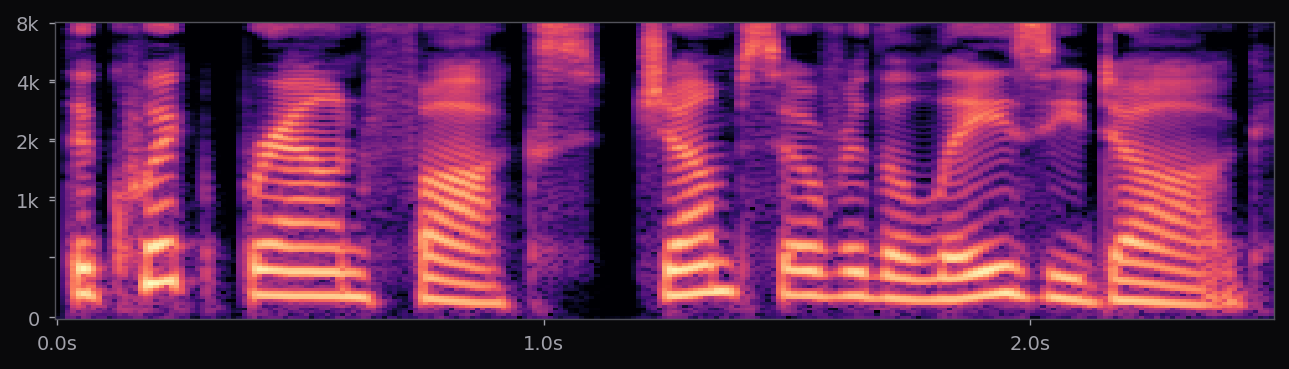
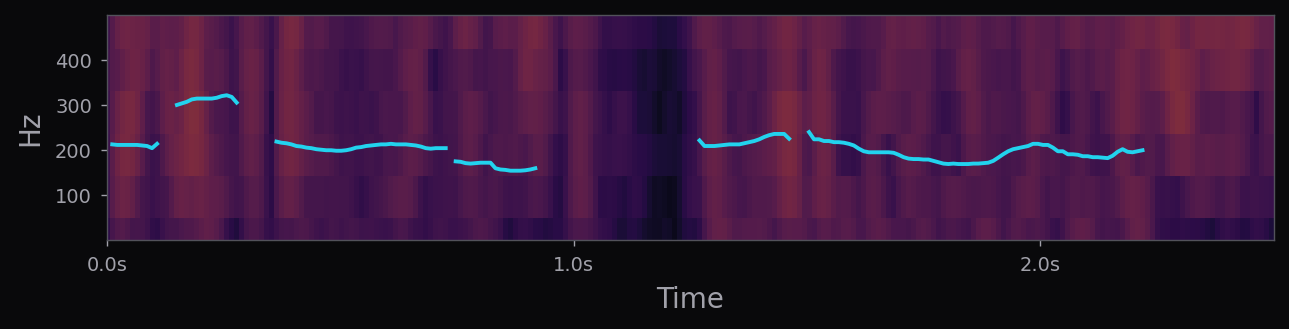
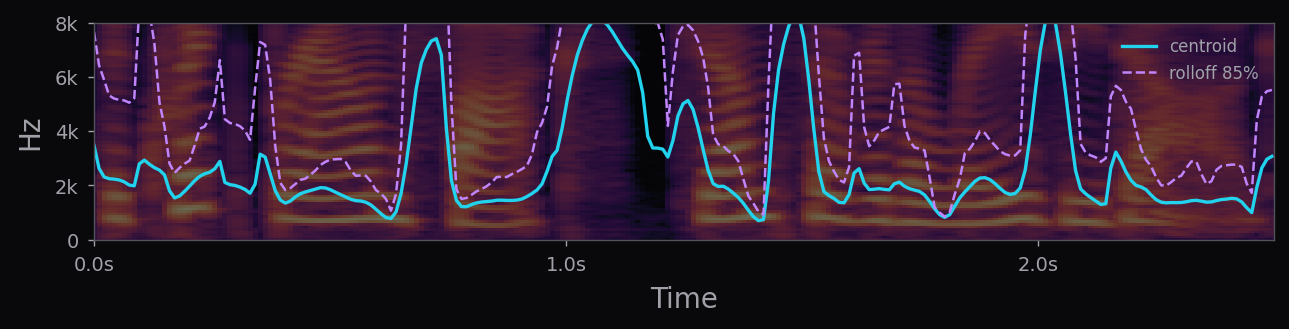
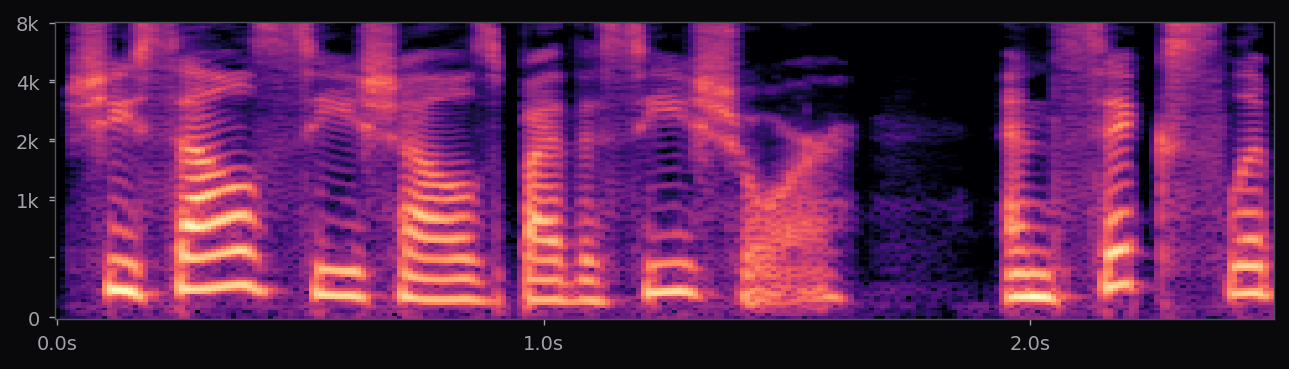
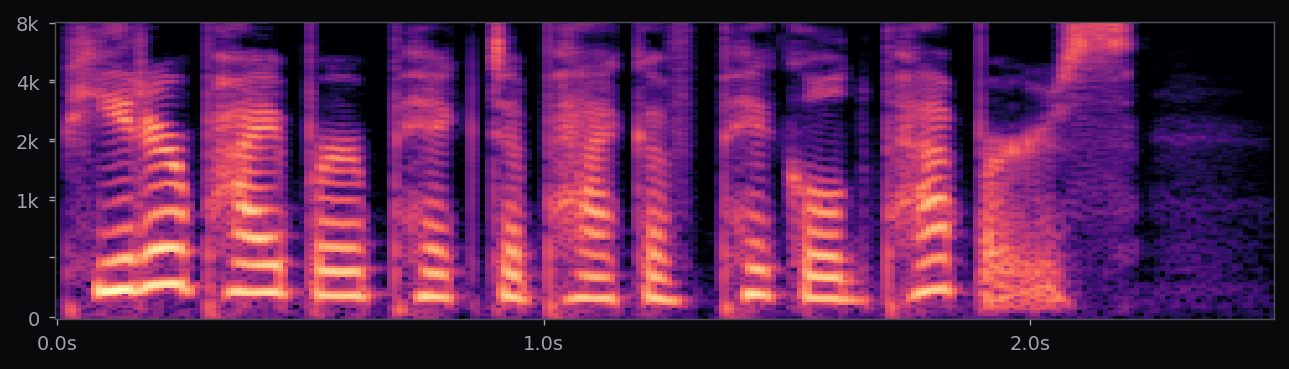
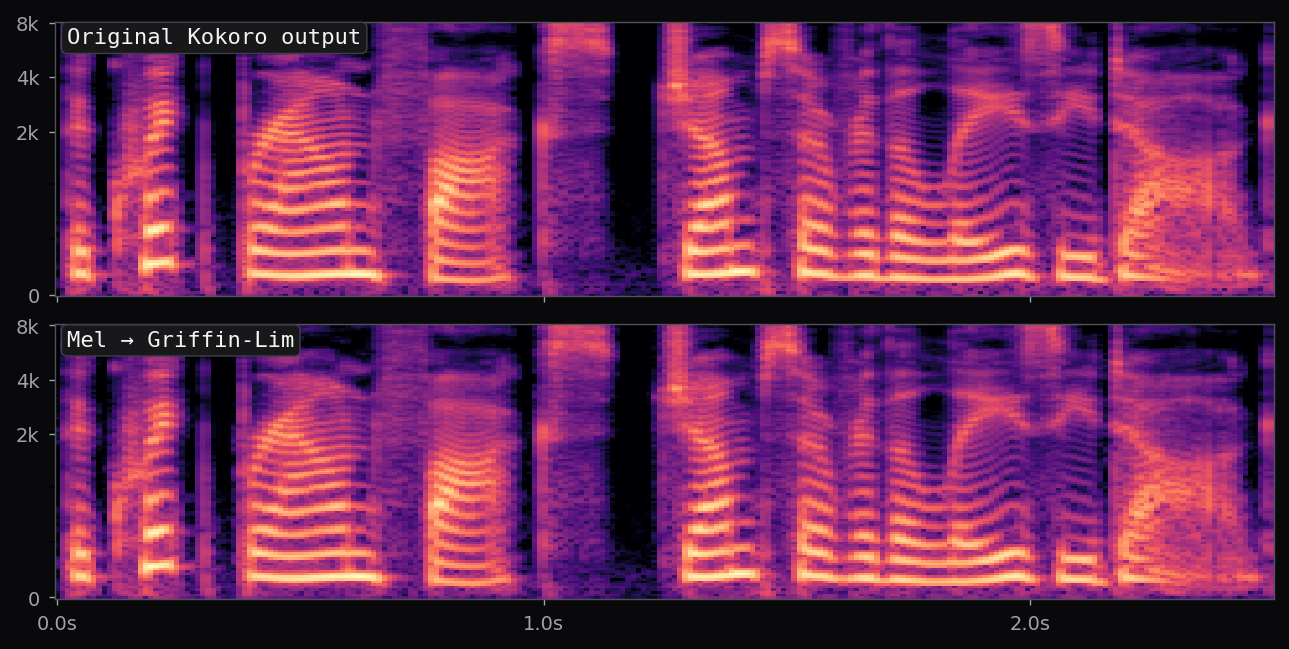
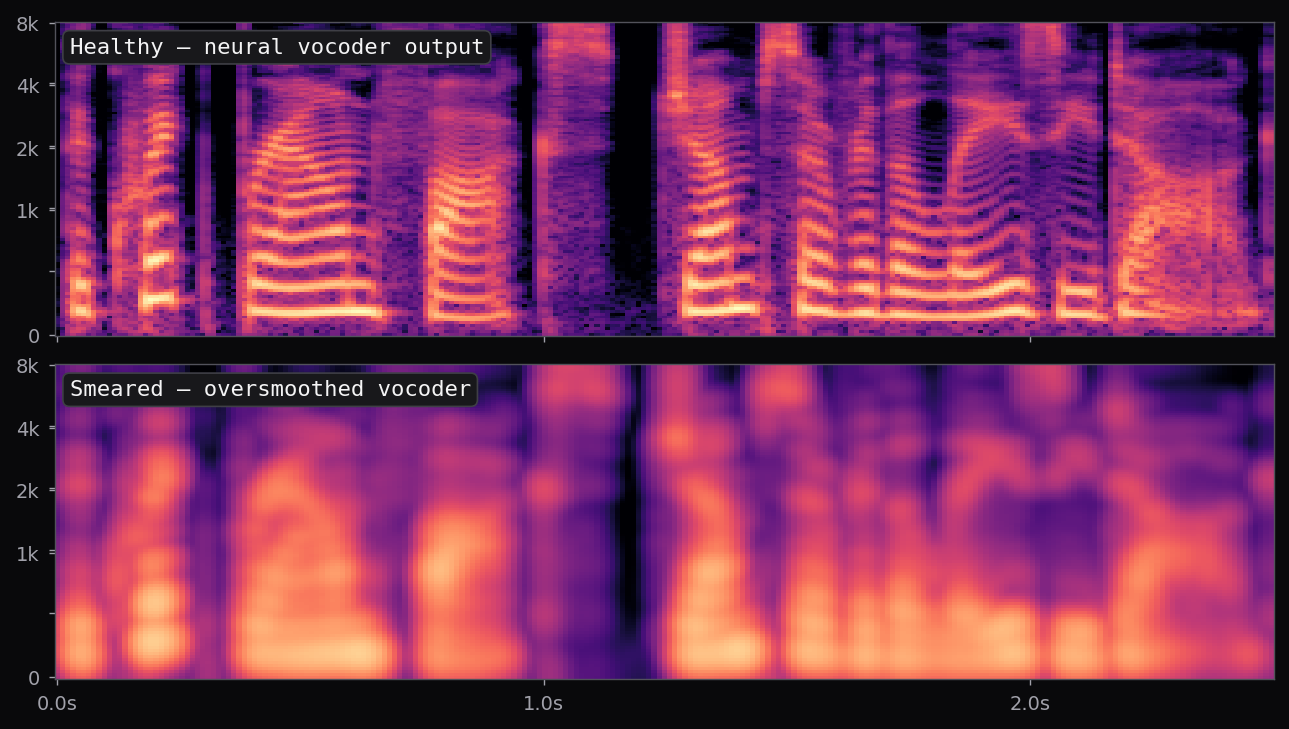
Kokoro-82M is a distillation and community-curated training of the StyleTTS2 architecture at roughly 82M parameters — about half the size of the reference StyleTTS2 release. The style diffusion step is pre-computed per voice and stored as a fixed embedding; inference is therefore a single forward pass through the acoustic model plus an iSTFTNet vocoder. End-to-end latency on a modern laptop CPU is under 400 ms for a full sentence.
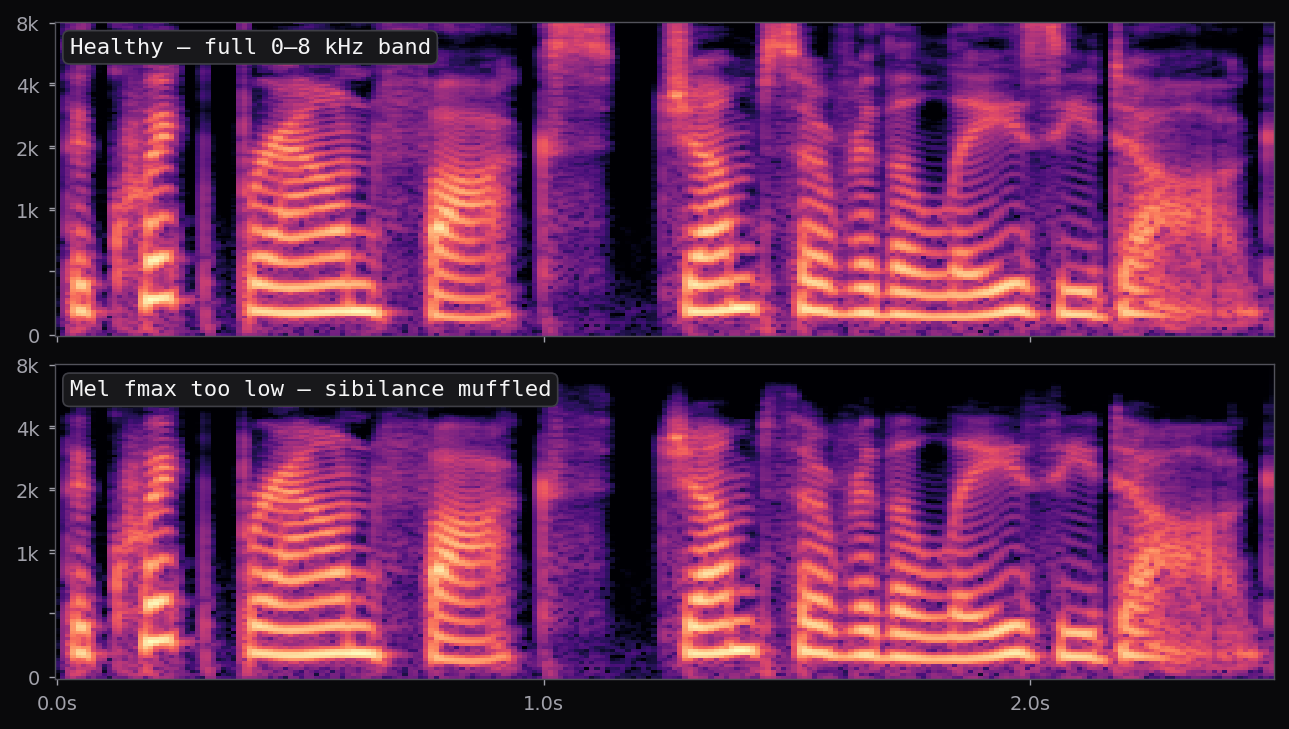
The af_heart, am_michael, and nine other voices used in the voice library above all ship with the stock Kokoro release. Apache 2.0 license. 54 voice packs at the time of writing, covering American, British, Japanese, Chinese, Spanish, French, Hindi, Italian, Portuguese. The spectrograms in this page's pipeline are rendered from audio that Kokoro generated locally, no API calls.
This is the end of the timeline, for now. The next entries will be the ElevenLabs and OpenAI comparison samples once their keys are wired in. The interesting thing is what the last 85 years have repeatedly shown: every representation introduced here — filter bank, spectrogram, LPC, formants, diphones, HMM parameters, mel-via-attention, dilated convolution audio, flow-matched codec tokens — is still visible somewhere in the pipeline on this page. The ladder is shorter than it looks.