The Standard for Scene Understanding
Before COCO, datasets like PASCAL VOC focused on iconic views of objects. COCO shifted the paradigm toward contextual understanding. Images contain multiple objects, often small, occluded, or in complex backgrounds. This forced the development of Feature Pyramid Networks (FPN) and more robust backbones.
Scale Variation
Objects range from a few pixels to the entire frame, requiring multi-scale feature extraction.
Non-Iconic Views
Objects are shown in natural settings, often partially hidden or at unusual angles.
Evaluation Metric
COCO uses Average Precision (AP) averaged over 10 IoU thresholds (0.50 to 0.95 with 0.05 steps). This rewards models with high localization accuracy.
- • AP50: AP at IoU=0.50
- • APS: AP for small objects (< 32² px)
- • APM: AP for medium objects
- • APL: AP for large objects
SOTA Evolution
The journey from early CNNs to modern Vision Transformers.
Detection Leaderboard
Official Leaderboard ↗| Rank | Model | Organization | Date | AP | Links |
|---|---|---|---|---|---|
| #1 | ScyllaNet | Scylla Technologies | 2025-09 | 66.1 | |
| #2 | CW_Detection | Independent | 2025-01 | 66.0 | |
| #3 | SenseTime Basemodel | SenseTime | 2024-11 | 66.0 | |
| #4 | Thinker | UBTECH | 2024-08 | 66.0 | |
| #5 | InternImage-H (OneFormer) | PJLab & Tsinghua | 2024-03 | 65.5 | |
| #6 | DINO-ViT-L | IDEA-Research | 2023-03 | 63.3 | |
| #7 | ViT-Adapter-L | Nanjing University | 2022-11 | 60.5 | |
| #8 | Swin-L (Cascade R-CNN) | Microsoft Research | 2021-07 | 58.9 |
Error Analysis
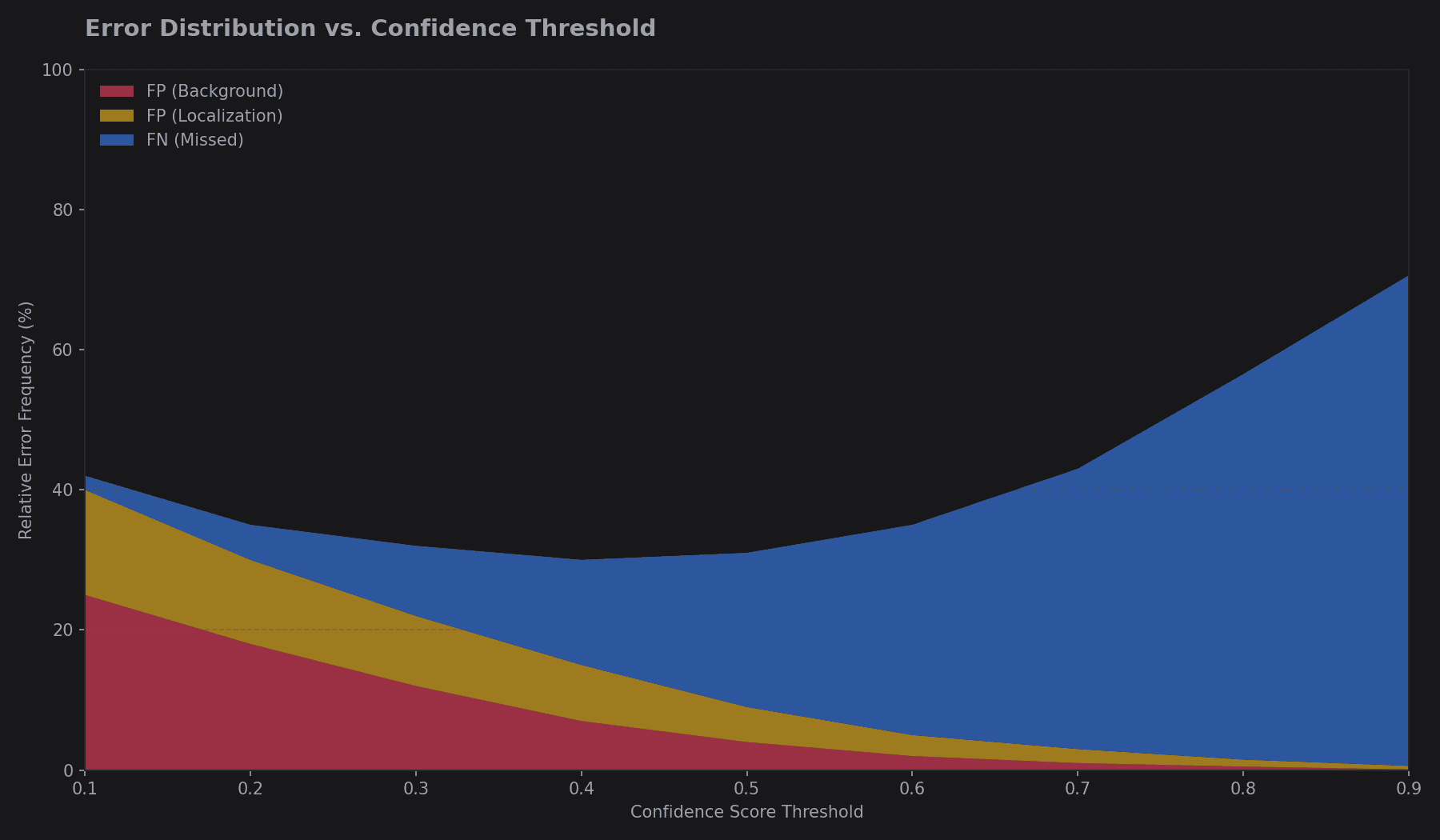
Most modern detectors struggle with False Positives on background textures and Localization Errors for small objects. COCO's analysis tools categorize errors into: Clutter, Similar Categories, and Poor Localization.
Speed vs. Accuracy
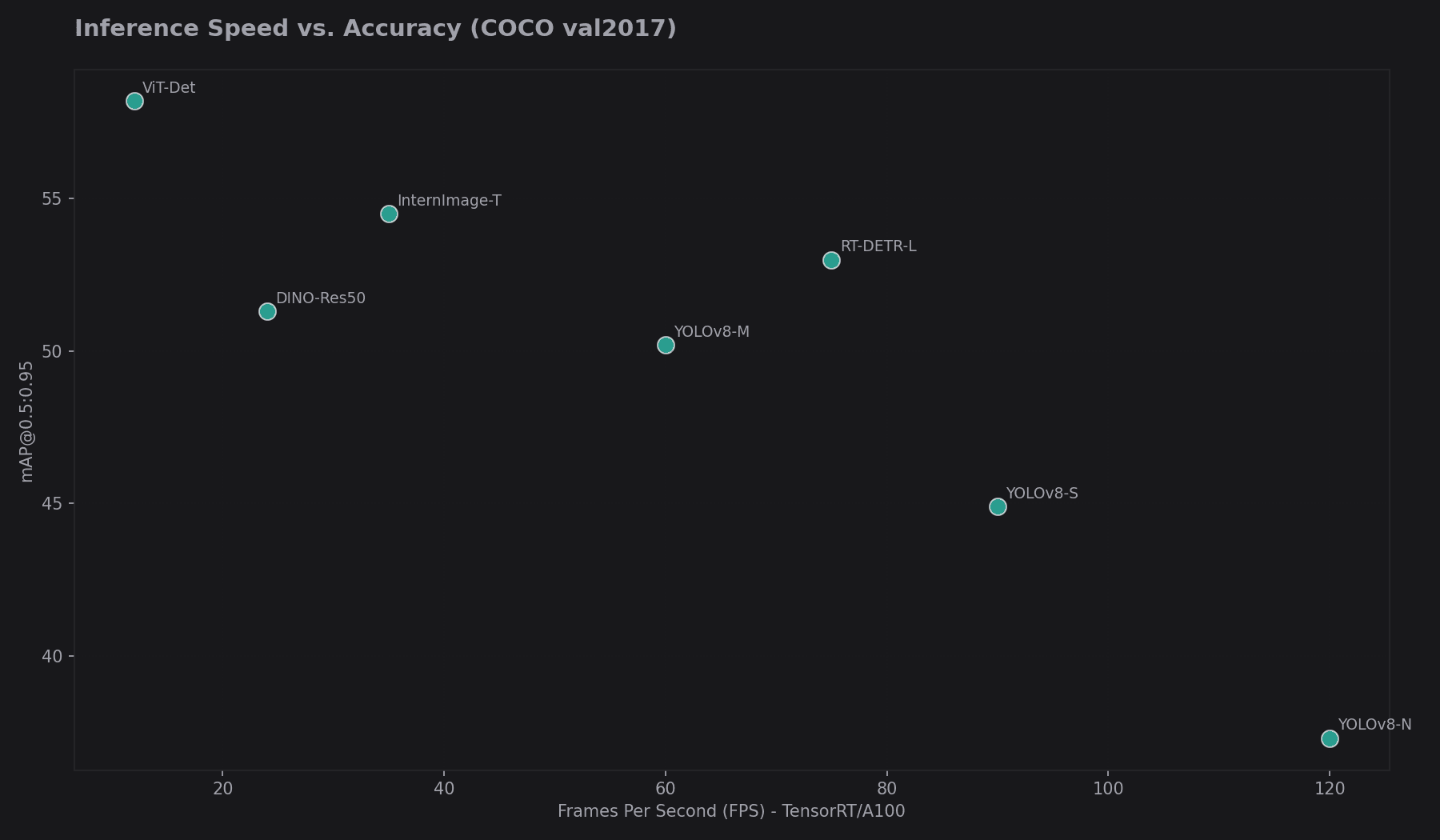
While SOTA models reach 60+ AP, they often run at < 5 FPS. Real-time models like YOLOv11 or RT-DETR target the 45-55 AP range while maintaining 100+ FPS on modern GPUs.
Dataset Variants
COCO 2017 Core
118k Train / 5k Val
Standard object detection & segmentation benchmark.
COCO-Stuff
164k Images
Adds 91 "stuff" categories (sky, grass, wall) for semantic context.
COCO-Keypoints
250k People
Human pose estimation with 17 annotated keypoints.
COCO-Captions
330k Images
5 natural language descriptions per image for multimodal tasks.
Foundational Papers
Comparison with Other Benchmarks
| Benchmark | Focus | Key Difference |
|---|---|---|
| LVIS | Long-tail recognition | 1000+ categories; addresses class imbalance better than COCO. |
| PASCAL VOC | Early detection | Smaller scale (20 classes), mostly centered objects. |
| Open Images | Massive scale | 9M images; uses image-level labels and bounding boxes. |
Ready to Benchmark?
Download the COCO 2017 dataset and start training your models. Use the official API for standardized evaluation.