What is SQuAD?
SQuAD quickly became the gold standard for evaluating question answering systems, driving rapid progress in neural language understanding. Unlike previous datasets that used multiple-choice formats, SQuAD requires models to identify the exact start and end indices of the answer within a passage.
The dataset evolved into SQuAD 2.0, which introduced a significant challenge: determining when a question is unanswerable based on the provided text. This forced models to not only find answers but also develop a "null" response capability, reducing hallucinations.
Original dataset where all questions have answers in the text.
Combines SQuAD 1.1 with 50,000 unanswerable questions written adversarially.
Key Innovations
- 1
Span-based format: Requiring models to select text spans rather than generating free-form text or choosing from options.
- 2
Large-scale: Over 100,000 pairs allowed for the first deep training of complex neural architectures like BiDAF and BERT.
- 3
Adversarial Unanswerability: SQuAD 2.0 introduced questions that look relevant but cannot be answered, testing true comprehension.
SOTA Evolution
The journey from feature engineering to Transformer dominance.
Official Leaderboard
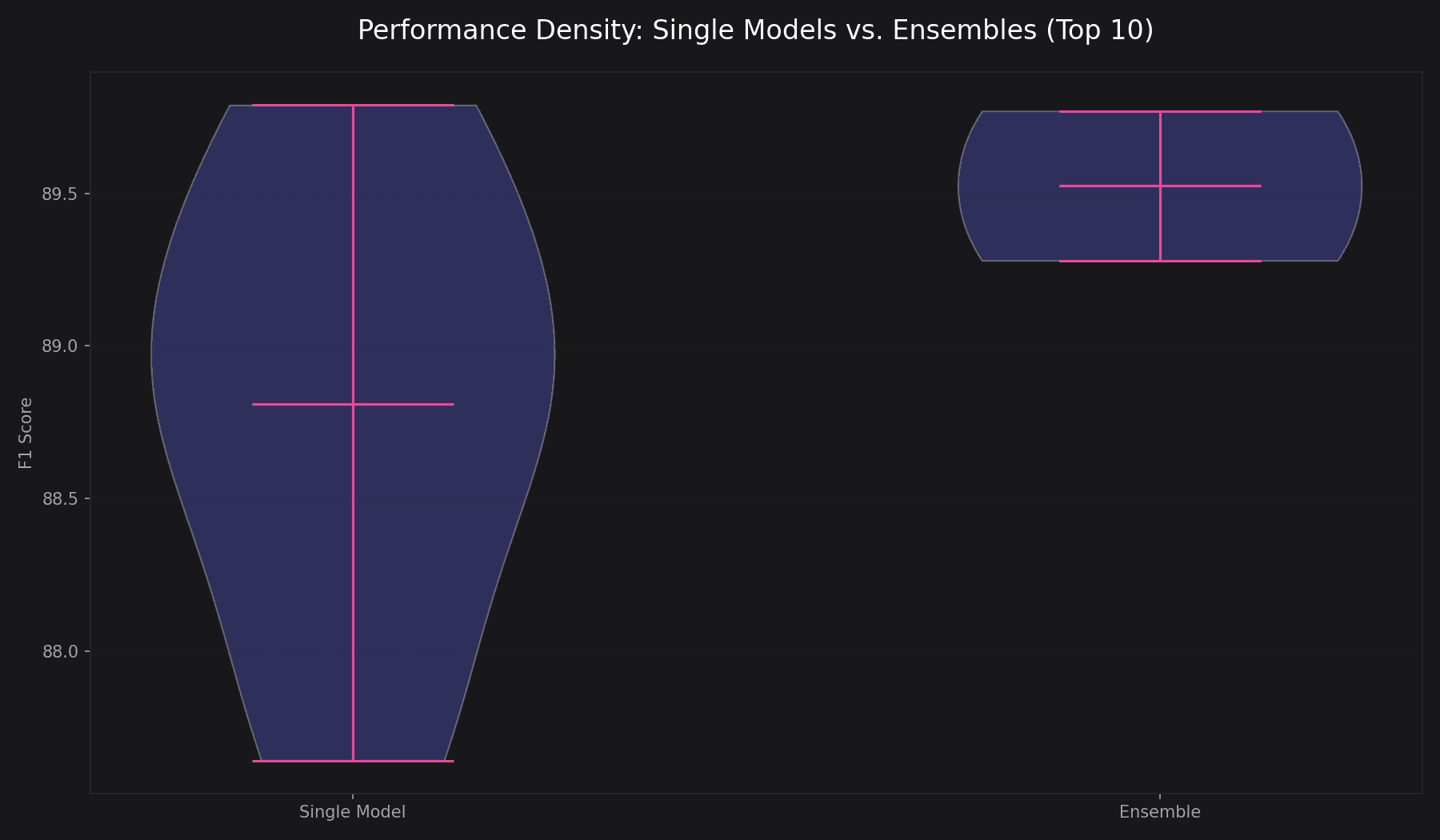
Top performing models on the SQuAD 2.0 hidden test set.
| Rank | Model | Vendor / Team | F1 Score | Date |
|---|---|---|---|---|
| #01 | RoBERTa (single model) single model | Facebook AI | 89.795 | Jul 2020 |
| #02 | Enhanced Albert+Verifier3 (ensemble) ensemble | Microsoft STCA AIC | 89.778 | May 2020 |
| #03 | RoBERTa+Verify (single model) single model | CW | 89.586 | Nov 2019 |
| #04 | BERT + ConvLSTM + MTL + Verifier (ensemble) ensemble | Layer 6 AI | 89.286 | Mar 2019 |
| #05 | Xlnet+Verifier (single model) single model | Google/CMU | 89.082 | Oct 2019 |
| #06 | Xlnet+Verifier (single model) single model | Ping An Life Insurance | 89.063 | Aug 2019 |
| #07 | BERT + DAE + AoA (single model) single model | HIT & iFLYTEK | 88.621 | Mar 2019 |
| #08 | SpanBERT (single model) single model | FAIR & UW | 88.709 | Jul 2019 |
| #09 | xlnet (single model) single model | Verified XiaoPAI | 88.000 | Sep 2019 |
| #10 | Insight-baseline-BERT (single model) single model | PAII Insight Team | 87.644 | Apr 2019 |
| #11 | Hanvon_model (single model) single model | Hanvon_WuHan | 87.117 | Sep 2019 |
| #12 | SLQA+ (single model) single model | Alibaba iDST | 87.021 | Jan 2018 |
Domain Adaptation Challenges
While SQuAD models achieve human-level performance on Wikipedia text, they often struggle when deployed to specialized domains. The heatmap below shows vocabulary overlap and context length disparities between SQuAD and specialized QA benchmarks.
Practitioner Tip
When fine-tuning SQuAD models for legal or medical domains, prioritize increasing the max_seq_length. SQuAD passages average 116 tokens, while CUAD (legal) can exceed 5,000.
Metric Explainer
Percentage of predictions that match one of the ground truth answers exactly.
The harmonic mean of precision and recall, measuring the overlap between prediction and truth at the token level.
Foundational Papers
Ready to train your model?
Download the SQuAD 2.0 dataset and join the leaderboard. Access the official training and development sets via the Stanford NLP group.