The NLU Paradigm Shift
Before GLUE, NLP research was fragmented. Models were often designed for single tasks—sentiment analysis, question answering, or natural language inference—making it difficult to measure general linguistic intelligence.
Introduced by researchers from NYU, DeepMind, and Facebook AI, GLUE established a multi-task evaluation paradigm. It forced models to share parameters across tasks, favoring architectures that learned robust, transferable representations of language rather than task-specific heuristics.
As BERT and its successors rapidly saturated GLUE, SuperGLUE was launched with harder tasks like coreference resolution and causal reasoning, featuring lower-resource training sets and more complex linguistic phenomena.
Aggregate Scoring
Single macro-average score across all tasks to rank general performance.
Private Test Sets
Held-out labels on a centralized server prevent data leakage and overfitting.
Task Category Distribution
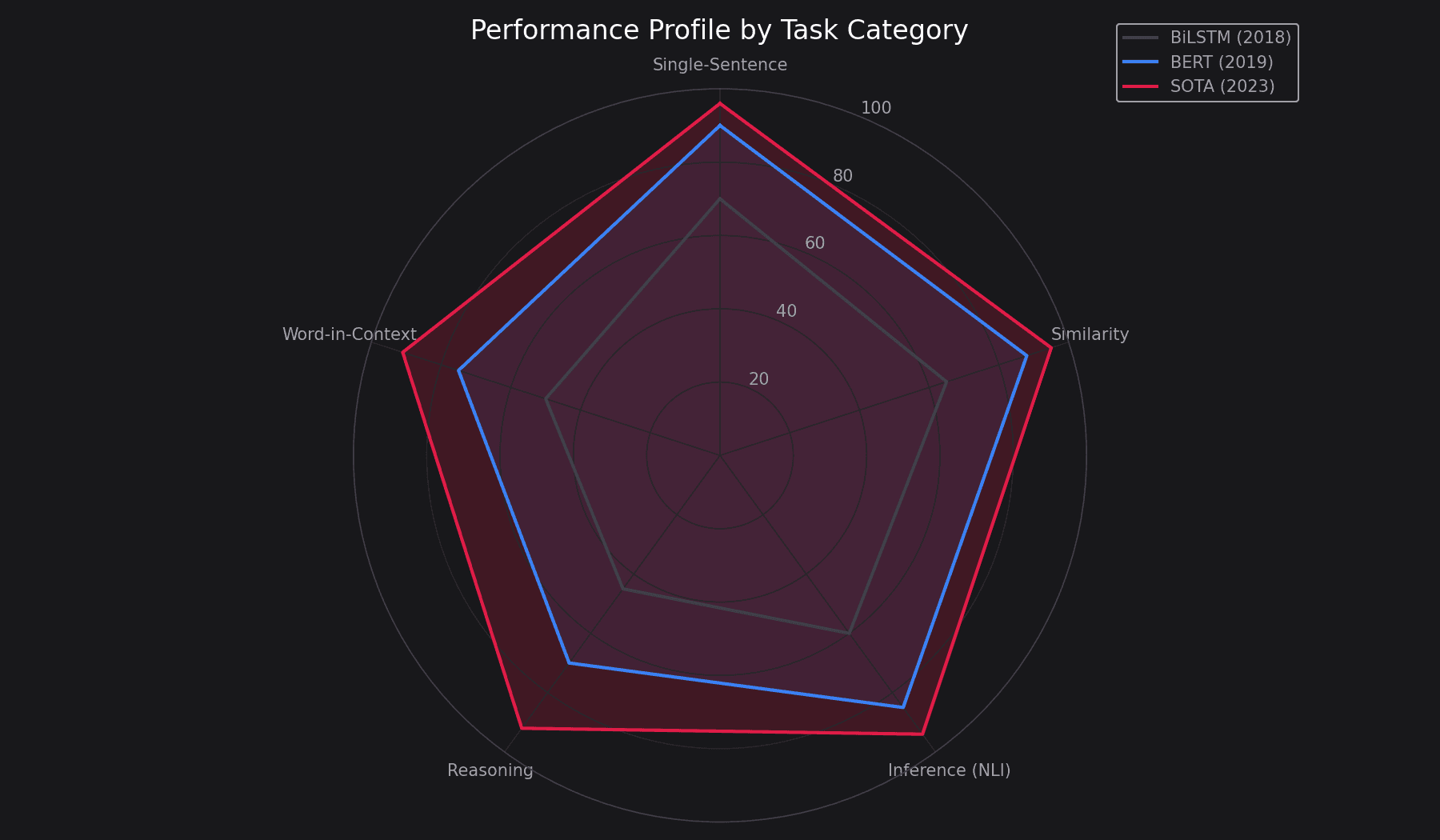
The Road to Parity (2018–2022)
Aggregate score progression from BERT to the final wave of SuperGLUE submissions.
SuperGLUE Leaderboard (Final Wave)
Rows show the official top submissions to super.gluebenchmark.com through 2022, when active competition ended. Each score links to its primary source. Entries that could not be independently sourced have been omitted rather than estimated.
| Rank | Model | Score | Metric | Organization | Date | Source | Type |
|---|---|---|---|---|---|---|---|
| 1 | Vega v2 (6B) | 91.3 | SuperGLUE avg | JD Explore Academy | 2022-10 | arxiv.org/abs/2212.01853 | Proprietary |
| 2 | ST-MoE-32B | 91.2 | SuperGLUE avg | Google Brain | 2022-02 | arxiv.org/abs/2202.08906 | Research |
| 3 | ERNIE 3.0 | 90.6 | SuperGLUE avg | Baidu | 2021-07 | arxiv.org/abs/2107.02137 | Proprietary |
| 4 | DeBERTa (ensemble) | 90.3 | SuperGLUE avg | Microsoft | 2021-01 | microsoft.com/research (DeBERTa blog) | Open-source |
| 5 | T5-11B | 89.3 | SuperGLUE avg | 2019-10 | arxiv.org/abs/1910.10683 | Open-source | |
| 6 | Human baseline | 89.8 | SuperGLUE avg | Wang et al. | 2019-05 | arxiv.org/abs/1905.00537 | Reference |
Note: The official SuperGLUE leaderboard has seen no meaningful new submissions since late 2022. Frontier LLMs (GPT-4/5, Claude, Gemini, Llama) are not represented here because their developers target MMLU, GPQA, BIG-Bench Hard, and HELM instead. Treat scores above as the endpoint of a saturated benchmark, not a current capability ranking.
Task Taxonomy
CoLA
MCCGrammatical acceptability (linguistic competence)
SST-2
AccBinary sentiment analysis of movie reviews
MRPC
F1/AccSemantic equivalence detection
STS-B
Pear/SpearSimilarity scoring (1-5 scale)
MNLI
AccNatural Language Inference (Entailment/Neutral/Contradiction)
BoolQ
AccYes/No questions based on passage context
COPA
AccCausal reasoning (Choice of Plausible Alternatives)
WSC
AccWinograd Schema Challenge (pronoun resolution)
ReCoRD
F1/EMReading comprehension with commonsense reasoning
Linguistic Diagnostic Suite
GLUE includes a curated set of "diagnostic" examples to test specific linguistic phenomena. Even models with high aggregate scores often struggle with these edge cases.
Models often ignore the 'not' and predict the same as the affirmative version.
Requires world knowledge to know 'it' refers to the trophy, not the suitcase.
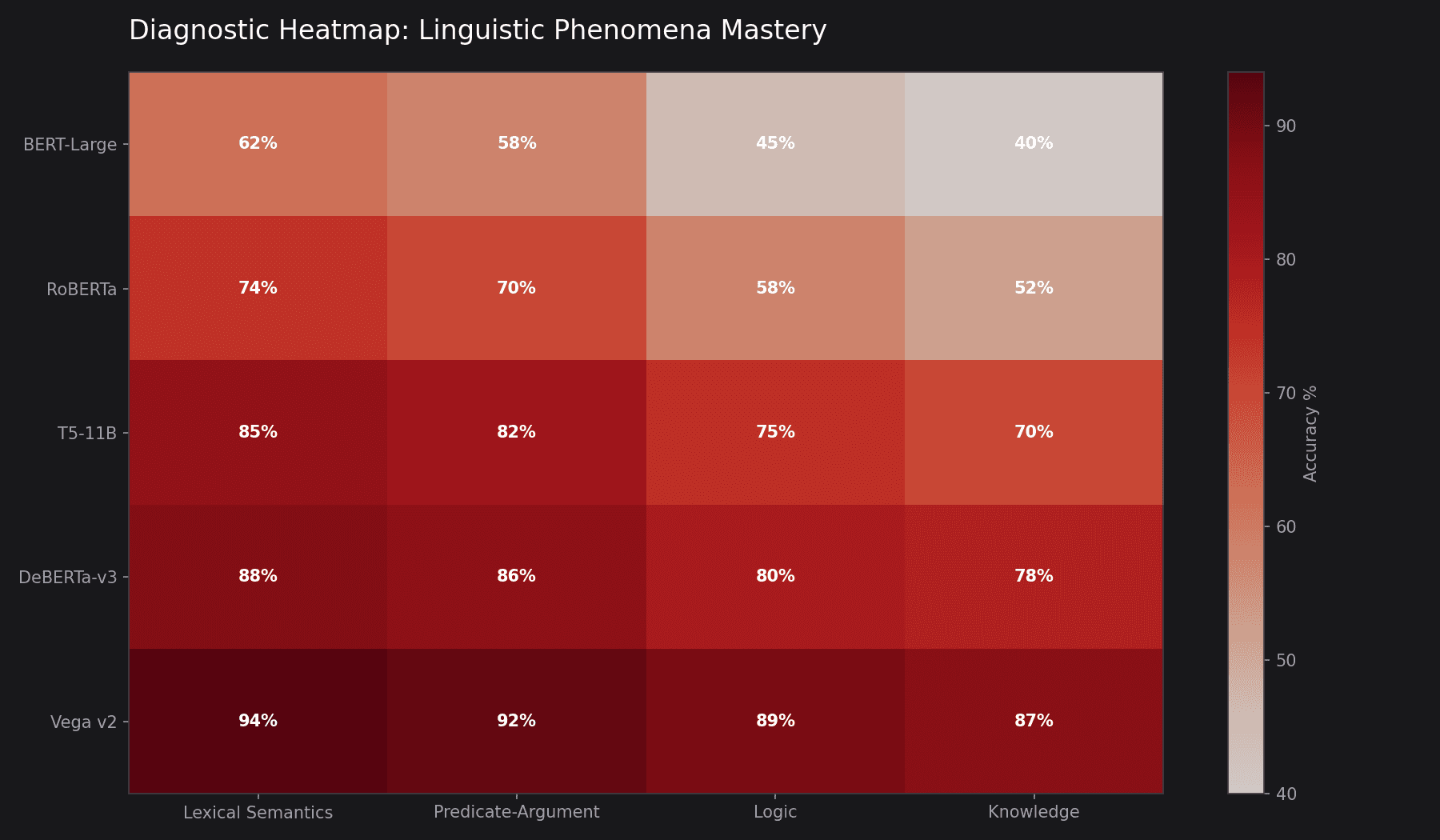
Diagnostic Heatmap
Visualization of model failures across 30+ linguistic categories including logic, lexical semantics, and predicate-argument structure.
Foundational Papers
GLUE: A Multi-Task Benchmark and Analysis Platform for NLU
SuperGLUE: A Stickier Benchmark for General-Purpose NLU
BERT: Pre-training of Deep Bidirectional Transformers
DeBERTa: Decoding-enhanced BERT with Disentangled Attention
Implementation & Tools
Official GLUE baseline implementations and evaluation toolkit.
Industry standard for fine-tuning on GLUE/SuperGLUE tasks.
Implementation of the model that dominated SuperGLUE for 2 years.
Text-to-Text Transfer Transformer framework for NLU.
Related Benchmarks
| Benchmark | Focus | Key Difference |
|---|---|---|
| MMLU | World Knowledge | Tests 57 subjects (STEM, Humanities) vs. NLU reasoning. |
| SQuAD | Reading Comprehension | Extractive QA on Wikipedia vs. multi-task classification. |
| HELM | Holistic Evaluation | Includes fairness, bias, and toxicity metrics. |
Using GLUE/SuperGLUE for research or teaching?
The datasets remain a clean, well-documented starting point for NLU work and transfer-learning experiments, even though the leaderboard itself has stopped drawing frontier submissions.